Incident thresholds define your tolerance to specific incidents that may occur on your network.
By their very nature, certain types of incidents may be more important than other types. By defining incident thresholds that match your business's service guarantees, you can use the network health report to provide an overall view of the compliance of your entire network at any given time (see Network Health Report).
The "Monitoring" training video, in which we cover "incident thresholds", is part of the "Network Operations" playlist:
- 1 of 5: Users and User Groups
- 2 of 5: Contacts
- 3 of 5: Scoping
- 4 of 5: Monitoring (below)
- 5 of 5: Reporting
Note: If you are new to Broadsign Control, we suggest you start with the Network Setup playlist.
Monitoring – Describes different aspects of network monitoring. You can find incident thresholds, in particular, at 8:00.
Monitoring
Your network's tolerance levels can be defined by incident type for all resources or by incident type for a specific resource.
If no threshold is assigned to an incident type, the incident is considered trivial and will not be interpreted as a Warning or Critical issue in the network health report.
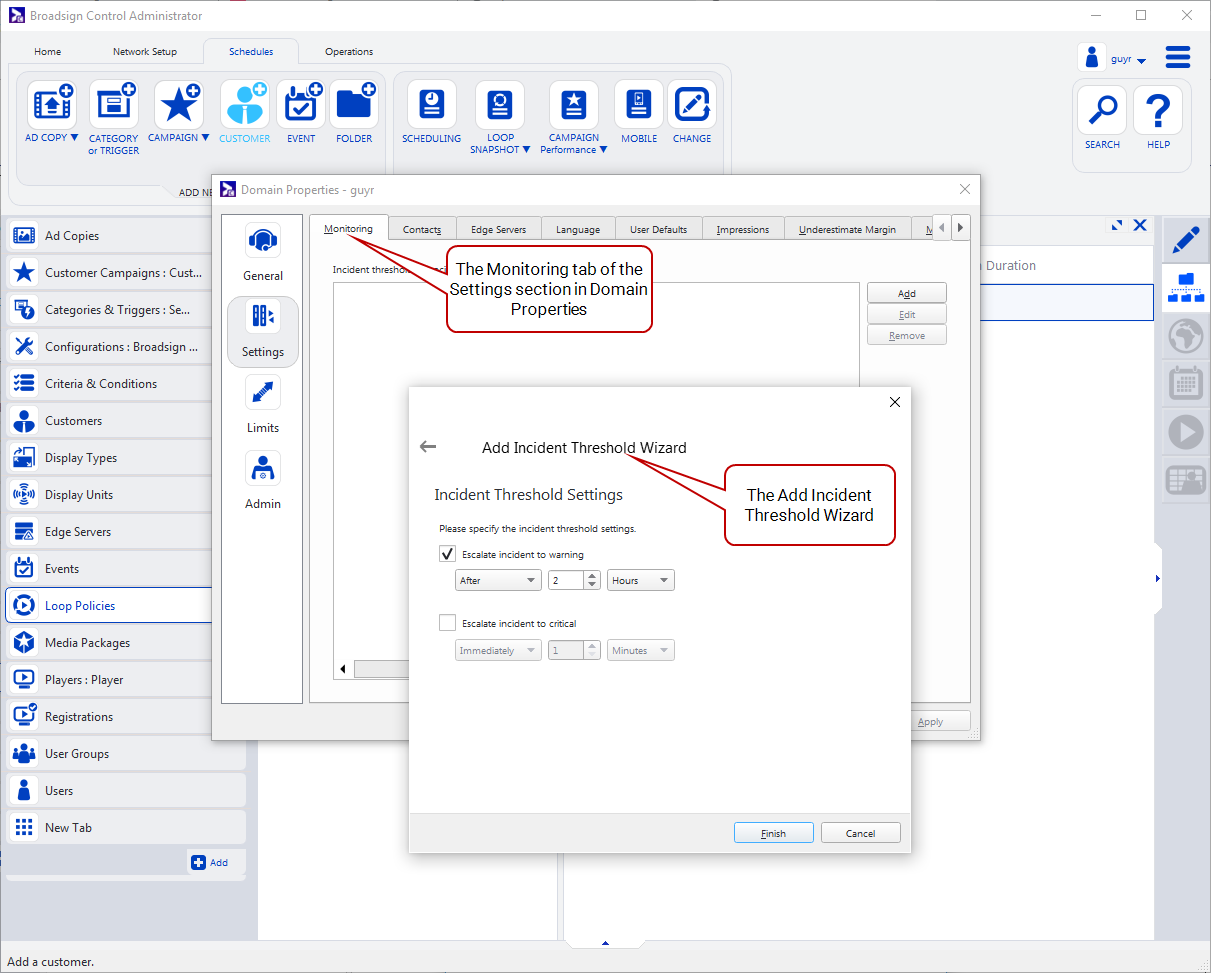
The incident thresholds specified in your domain's Monitoring tab serve as your network-wide defaults for any given incident type. Optionally, you can override this default for a particular resource by assigning an incident threshold to the resource in its Monitoring tab. For each threshold, you can define how and when the incident is escalated to a warning or critical status.
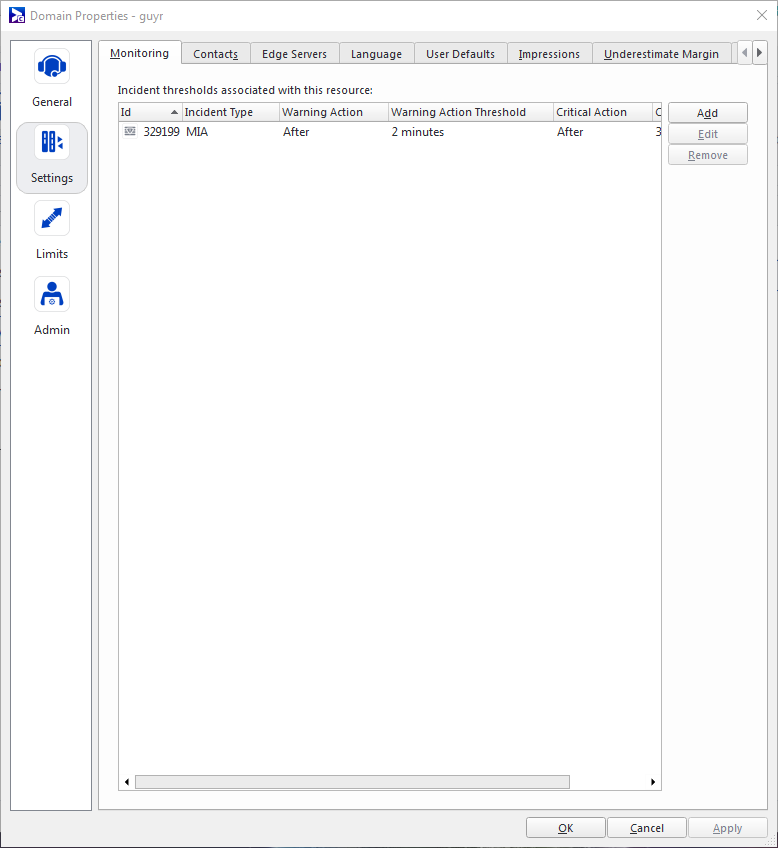
Incident Thresholds govern how incidents are escalated to Warnings and Critical issues. The escalation of an incident’s status is performed automatically by Broadsign Server and email notifications are sent out to the proper contacts when escalation occurs. Modifying an incident threshold will retroactively adjust the statuses of incidents that have already been escalated.
Consider this example of a Missing in Action incident (MIA):
Example: By setting a threshold on the MIA incident at the Domain level, you can define your network-wide tolerance to MIA as follows: Warning after two hours, Critical after six hours. This business rule will be respected in the Network Health Report and the Service Panel for the Player.
- If a player has been MIA for less than two hours, then the Network Health report will still consider that player as healthy (see Network Health Report).
- If a network health report is generated three hours after the player has gone MIA, the player will appear as having a warning.
- If a network health report is generated more than six hours after the player has gone MIA, the player will appear as being critical.
Consider this example of a connectivity issue:
Example: A network comprised of mixed broadband and dial-up players needs to be monitored for its connectivity status. The tolerance to MIAs on dial-up players will most likely be higher, due to the unreliability of the connection. In this case, you can set a custom threshold for the MIA incident on the player resource that will override the threshold set in the Domain:
- Warning after twelve hours
- Critical after two days
This change ensures that when the network health report is generated, the state of this dial-up player will depend on its own threshold, not the network-wide threshold.
Here are some other examples of how to use custom thresholds:
- A high-value player in Times Square should have a lower tolerance to incidents than other players in the same network.
- A Device Control Operation that turns a display on is more important than one that turns the display off.
- If a particular ad copy is causing incidents that are expected, they can be suppressed so that they do not count in the network health report.
